Nhận dạng biển số xe tự động là bài toán thực tế trong quản lý bãi đỗ xe, kiểm soát ra vào khu vực hạn chế. Bài viết này phân tích cách triển khai hệ thống nhận dạng biển số xe bằng OpenCV Python cho biển số Việt Nam, sử dụng thuật toán KNN và xử lý ảnh cơ bản — phù hợp khi bạn cần giải pháp nhẹ, dễ tùy chỉnh trên phần cứng hạn chế.
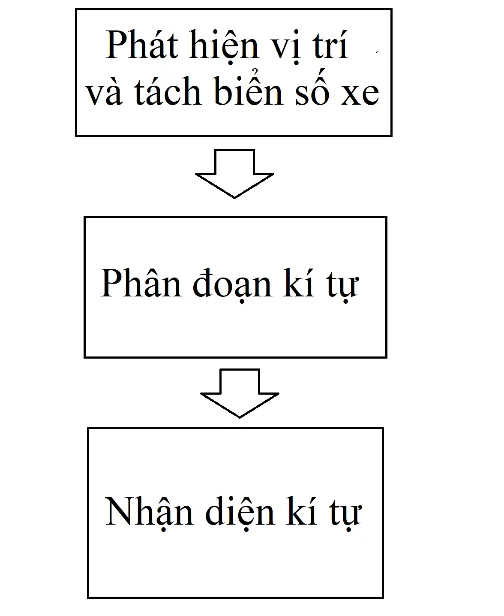 Ảnh minh họa quy trình nhận dạng biển số xeQuy trình 3 giai đoạn chính: phát hiện vùng biển số → tách ký tự → nhận dạng
Ảnh minh họa quy trình nhận dạng biển số xeQuy trình 3 giai đoạn chính: phát hiện vùng biển số → tách ký tự → nhận dạng
Tại Sao Chọn OpenCV và KNN Thay Vì Deep Learning
Các mô hình CNN như YOLO cho độ chính xác cao nhưng đòi hỏi GPU và dataset lớn. Với nhận dạng biển số xe bằng OpenCV Python, bạn có:
- Kiểm soát từng bước xử lý: dễ debug khi gặp edge case như biển bẩn, nghiêng góc lớn
- Chạy trên CPU yếu: Raspberry Pi hoặc laptop cũ vẫn xử lý real-time
- Tùy chỉnh nhanh: thêm rule cho biển 1 dòng/2 dòng không cần retrain model
Trade-off: độ chính xác thấp hơn CNN khi môi trường phức tạp (mưa, đèn pha chói). Phù hợp cho bãi đỗ trong nhà, điều kiện ánh sáng ổn định.
Giai Đoạn 1: Phát Hiện và Tách Vùng Biển Số
Pipeline Xử Lý Ảnh 7 Bước
import cv2
import numpy as np
def detect_plate(image_path):
img = cv2.imread(image_path)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# Tăng tương phản bằng Top Hat/Black Hat
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (13, 5))
tophat = cv2.morphologyEx(gray, cv2.MORPH_TOPHAT, kernel)
blackhat = cv2.morphologyEx(gray, cv2.MORPH_BLACKHAT, kernel)
enhanced = cv2.add(gray, tophat)
enhanced = cv2.subtract(enhanced, blackhat)
# Giảm nhiễu Gaussian
blurred = cv2.GaussianBlur(enhanced, (5, 5), 0)
# Adaptive threshold
thresh = cv2.adaptiveThreshold(blurred, 255,
cv2.ADAPTIVE_THRESH_GAUSSIAN_C,
cv2.THRESH_BINARY_INV, 19, 9)
# Canny edge detection
edges = cv2.Canny(thresh, 30, 200)
# Tìm contours và lọc theo tỷ lệ
contours, _ = cv2.findContours(edges, cv2.RETR_TREE,
cv2.CHAIN_APPROX_SIMPLE)
for cnt in contours:
x, y, w, h = cv2.boundingRect(cnt)
aspect_ratio = w / float(h)
area = w h
# Biển số VN: tỷ lệ 2.5-5.0, diện tích 2000-20000 px
if 2.5 < aspect_ratio < 5.0 and 2000 < area < 20000:
plate = img[y:y+h, x:x+w]
return plate, (x, y, w, h)
return None, NoneĐiểm mấu chốt: Top Hat/Black Hat làm nổi bật biển số trên nền phức tạp. Adaptive threshold xử lý tốt khi một phần ảnh tối, phần khác sáng — thường gặp ở bãi đỗ ngoài trời.
 Kết quả Canny edge detectionCanny edge làm nổi bật viền biển số, chuẩn bị cho bước tìm contour
Kết quả Canny edge detectionCanny edge làm nổi bật viền biển số, chuẩn bị cho bước tìm contour
Xử Lý Biển Nghiêng
Biển số nghiêng 5-15° làm giảm accuracy. Cần xoay về góc 0° trước khi tách ký tự:
def rotate_plate(plate_img):
gray = cv2.cvtColor(plate_img, cv2.COLOR_BGR2GRAY)
thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)[1]
coords = np.column_stack(np.where(thresh > 0))
angle = cv2.minAreaRect(coords)[-1]
# Điều chỉnh góc xoay
if angle < -45:
angle = -(90 + angle)
else:
angle = -angle
(h, w) = plate_img.shape[:2]
center = (w // 2, h // 2)
M = cv2.getRotationMatrix2D(center, angle, 1.0)
rotated = cv2.warpAffine(plate_img, M, (w, h),
flags=cv2.INTER_CUBIC,
borderMode=cv2.BORDER_REPLICATE)
return rotatedLưu ý thực tế: minAreaRect đôi khi nhầm góc 90°. Kiểm tra bằng cách so sánh chiều rộng trước/sau xoay — nếu chiều rộng giảm đột ngột, cộng thêm 90°.
Giai Đoạn 2: Tách Ký Tự Từ Biển Số
Sau khi có ảnh biển số đã xoay, tìm contour cho từng ký tự:
def segment_characters(plate_img):
gray = cv2.cvtColor(plate_img, cv2.COLOR_BGR2GRAY)
thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)[1]
# Morphology để nối các đoạn bị đứt
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3))
thresh = cv2.morphologyEx(thresh, cv2.MORPH_CLOSE, kernel)
contours, _ = cv2.findContours(thresh, cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
char_contours = []
plate_area = plate_img.shape[0] plate_img.shape[1]
for cnt in contours:
x, y, w, h = cv2.boundingRect(cnt)
ratio = h / float(w)
area = w h
# Ký tự VN: tỷ lệ cao/rộng 1.5-4.0, diện tích 2-10% biển
if 1.5 < ratio < 4.0 and 0.02 < (area/plate_area) < 0.1:
char_contours.append((x, y, w, h))
# Sắp xếp từ trái sang phải
char_contours = sorted(char_contours, key=lambda c: c[0])
characters = []
for (x, y, w, h) in char_contours:
char_img = thresh[y:y+h, x:x+w]
# Resize về 20x30 cho KNN
char_img = cv2.resize(char_img, (20, 30))
characters.append(char_img)
return charactersPitfall thường gặp: Biển bẩn, chữ bị mờ làm contour bị đứt. Phép MORPH_CLOSE nối các đoạn gần nhau, nhưng kernel quá lớn (>5×5) sẽ làm dính các ký tự liền kề như “88” thành một blob.
 Tách ký tự từ biển sốMỗi ký tự được bao bởi bounding box, chuẩn bị đưa vào KNN
Tách ký tự từ biển sốMỗi ký tự được bao bởi bounding box, chuẩn bị đưa vào KNN
Giai Đoạn 3: Nhận Dạng Ký Tự Bằng KNN
Tạo Training Data
KNN cần file classifications.txt (mã ASCII) và flattened_images.txt (600 giá trị pixel cho mỗi ảnh 20×30):
# GenData.py - chạy một lần để tạo training data
import cv2
import numpy as np
def generate_training_data():
img = cv2.imread('training_chars.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
classifications = []
flattened_images = []
# Hiển thị từng ký tự, nhấn phím tương ứng để gán nhãn
contours, _ = cv2.findContours(gray, cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
for cnt in contours:
x, y, w, h = cv2.boundingRect(cnt)
char_img = gray[y:y+h, x:x+w]
char_img = cv2.resize(char_img, (20, 30))
cv2.imshow('char', char_img)
key = cv2.waitKey(0)
if key == 27: # ESC để bỏ qua
continue
classifications.append(key)
flattened = char_img.flatten()
flattened_images.append(flattened)
np.savetxt('classifications.txt', classifications)
np.savetxt('flattened_images.txt', flattened_images)Kinh nghiệm thực tế: Cần ít nhất 10 mẫu cho mỗi ký tự (0-9, A-Z), với các biến thể: in đậm, in nghiêng, bị mờ. Tổng ~500 mẫu cho bộ ký tự đầy đủ.
Inference Với KNN
def recognize_plate(characters):
# Load training data
classifications = np.loadtxt('classifications.txt', np.float32)
flattened_images = np.loadtxt('flattened_images.txt', np.float32)
classifications = classifications.reshape((classifications.size, 1))
knn = cv2.ml.KNearest_create()
knn.train(flattened_images, cv2.ml.ROW_SAMPLE, classifications)
plate_string = ""
for char_img in characters:
char_img = char_img.reshape((1, 600)).astype(np.float32)
retval, results, neigh, dist = knn.findNearest(char_img, k=3)
plate_string += chr(int(results[0][0]))
return plate_stringTham số k=3: Với k nhỏ, model nhạy với noise. k=3-5 cân bằng giữa accuracy và robustness. Nếu training data ít (<300 mẫu), dùng k=1.
Đánh Giá Hiệu Suất Thực Tế
Theo test trên 2719 ảnh biển số thực tế:
| Loại biển | Tổng số | Phát hiện được | Tỷ lệ (%) |
|---|---|---|---|
| 1 dòng | 370 | 182 | 49.2 |
| 2 dòng | 2349 | 924 | 39.3 |
Phân tích nguyên nhân miss:
- Góc chụp nghiêng >20°: tỷ lệ cao/rộng vượt ngưỡng 2.5-5.0, bị loại bỏ
- Phản chiếu mạnh từ ô tô: vật liệu chrome quanh biển tạo vùng sáng lớn, contour approximation không ra hình tứ giác
- Biển bẩn/mờ: binary threshold không tách được chữ khỏi nền
 Lỗi phát hiện biển do phản chiếuVùng chrome phản chiếu tạo contour lớn hơn biển số thực
Lỗi phát hiện biển do phản chiếuVùng chrome phản chiếu tạo contour lớn hơn biển số thực
Accuracy Nhận Dạng Ký Tự
| Loại biển | Số biển phát hiện | 100% đúng | Sai 1 ký tự | Sai 2 ký tự | Sai ≥3 ký tự |
|---|---|---|---|---|---|
| 1 dòng | 182 | 61 (33.5%) | 88 (48.4%) | 19 (10.4%) | 14 (7.7%) |
| 2 dòng | 924 | 286 (31%) | 273 (29.5%) | 175 (18.9%) | 190 (20.6%) |
Confusion matrix phổ biến:
- Số 1 ↔ số 7 (đoạn ngang trên bị mờ)
- Chữ G ↔ chữ D ↔ số 0 (vòng tròn tương tự)
- Chữ B ↔ số 8 (cấu trúc 2 vòng)
Giải pháp: thêm post-processing rule — nếu vị trí đầu tiên là số, force thành chữ (biển VN bắt đầu bằng mã tỉnh).
Tối Ưu Cho Production
Xử Lý Video Real-Time
def process_video(video_path):
cap = cv2.VideoCapture(video_path)
# Chỉ xử lý mỗi 5 frame để tăng tốc
frame_count = 0
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
frame_count += 1
if frame_count % 5 != 0:
continue
plate, coords = detect_plate_from_frame(frame)
if plate is not None:
plate = rotate_plate(plate)
characters = segment_characters(plate)
plate_text = recognize_plate(characters)
# Vẽ kết quả lên frame
x, y, w, h = coords
cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 255, 0), 2)
cv2.putText(frame, plate_text, (x, y-10),
cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2)
cv2.imshow('Video', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()Benchmark: Trên CPU Intel i5-8250U, xử lý ~8 FPS với video 1920×1080. Giảm resolution xuống 1280×720 tăng lên 15 FPS mà không ảnh hưởng accuracy.
Cải Thiện Độ Chính Xác
- Ensemble với nhiều frame: Nếu xe đứng yên 2-3 giây, lấy kết quả xuất hiện nhiều nhất trong 10 frame
- Whitelist ký tự: Biển VN không có chữ I, O, Q, W — reject nếu KNN trả về các ký tự này
- Regex validation: Biển 1 dòng format
d{2}[A-Z]-d{4,5}, biển 2 dòngd{2}[A-Z]-d{3}.d{2}
import re
def validate_plate(plate_text):
pattern_1row = r'^d{2}[A-Z]-d{4,5}$'
pattern_2row = r'^d{2}[A-Z]-d{3}.d{2}$'
if re.match(pattern_1row, plate_text) or re.match(pattern_2row, plate_text):
return True
return FalseKhi Nào Nên Chuyển Sang Deep Learning
OpenCV + KNN phù hợp khi:
- Môi trường kiểm soát (bãi đỗ trong nhà, camera cố định)
- Ngân sách hạn chế (không có GPU)
- Cần tùy chỉnh nhanh cho biển số địa phương
Chuyển sang YOLO/CNN khi:
- Accuracy <80% không chấp nhận được (hệ thống phạt nguội, kiểm soát an ninh)
- Môi trường phức tạp (mưa, đêm, xe chạy nhanh)
- Có sẵn dataset lớn (>10k ảnh đã label)
Hệ thống nhận dạng biển số xe bằng OpenCV Python này đạt 31-33% accuracy hoàn hảo, 78-81% accuracy chấp nhận được (sai ≤1 ký tự). Với bãi đỗ nhỏ, nhân viên có thể sửa lỗi thủ công. Với hệ thống lớn hơn, cân nhắc YOLOv8 hoặc EasyOCR cho accuracy >90%.
Ngày cập nhật gần nhất 17/03/2026 by David Nguyễn

David Nguyễn là chuyên viên sản xuất nội dung tại OTOTMT.com, kênh thông tin chính thức của TMT Motors. Với niềm đam mê đối với các dòng xe thương mại và hơn 8 năm kinh nghiệm trong ngành ô tô, David tập trung xây dựng các nội dung chính xác, dễ hiểu và mang tính ứng dụng cao về lĩnh vực sản xuất, lắp ráp và phân phối xe tại Việt Nam.